Choosing a New Version Control System
The last several years have brought a frenzy of activity on the version control front. Subversion has been joined by Mercurial, Bazaar, Git, Monotone, Darcs, and many more. With all of them touting their abilities over the other, it’s become confusing to pick which one is right for you and your company. I’ve spent the last year and a half evaluating options for my company, watching the development of many of the projects, the community interactions, the feature set, the issues, and generally pushing the boundaries of what I could do with a subset of them.
For the record: I am involved with Subversion development, although to a much lesser degree these days. Some may see this as a bias, but I think it gives me insight into the tool and what it’s really capable of.
The Starting Point: Subversion
At this point, we have Subversion. For the most part, it suits our needs pretty well. We don’t have a lot of branching and merging, we tend to develop features in small well-defined chunks and keep that development on trunk as much as possible. Our projects are of varied sizes, ranging from small (thousands of lines of code) to large (millions of lines of code, not all of which is ours). We tend to work in smaller teams (2-3), but occasionally grow the team larger (6-8).
The Pros
Subversion Just Works. It’s easy to grasp. The devs spent a great deal of time making sure the user interface was sound, that the terminology was well-defined, and interactions with Subversion were consistent. Newbies can get up and running in pretty short period of time, thanks to the immense amount of documentation, great books, and toolage (e.g., TortoiseSVN) that is out there. Out of the box, you get access controls (necessary in my environment), the ability to read-only or write-through proxies, your choice of hosting (ssh, svn, http, https), all the authentication mechanisms present in Apache, or Cyrus SASL (depending on your chosen method of hosting), and more. Subversion also recognized that others in the Enterprise need to use it, so it’s extremely capable when it comes to handling many large files. It won’t chew up all the memory on your machine or server, because it’s designed to operate on streams of data at its core.
In summary, Subversion is a well thought-out, enterprise solution. Especially, when you consider it’s age.
The Cons
Where Subversion breaks down for us, is in the same places others have been yelling about for a while: merge tracking and renaming tracking.
Merge tracking is less important to us. We don’t branch much, and when we do, they’re usually not long lived except for stable branches. There are exceptions, we have done those things, we just don’t feel the pain of them as often as others. When we do, it stings a bit, but then the pain is gone.
What does hurt us much more often is the lack of rename tracking. We’re very concerned about the organization of our code, and tree re-organizations wreak havoc on productivity because Subversion tries to re-instate a moved file instead of updating the file using its new name.
Rename tracking is a known problem, and I’m confident that it will get solved for Subversion. It will take a while; it’s versioning policies do make it more difficult, but not impossible to do. It’s also those same versioning policies that have allowed many projects to build support for Subversion and not worry that things are going to break tomorrow. It’s a double-edged sword.
The Big Four
I couldn’t sit and evaluate every solution that was on the table, unfortunately. So fairly quickly, I had to narrow down what I was looking at. The number one metric for doing that was: community. Having been involved with Subversion early on, it was community that made the real difference between the success and failure of an open source project. Following that was adoption by others. Simply put: it doesn’t matter if you have the best tool for the job if no one is helping to integrate it into the tools you need to use everyday (IDEs, Continuous Integration tools, Bug Trackers, etc.), or you’re the only person using it. A developer’s job is hard enough without having to worry whether something foundational as your version control tool was going to be a hinderance every step of the way.
Darcs and Monotone, while having some truly interesting approaches, just didn’t have the community and adoption that I was looking for. But I do keep an eye on the projects, because they’ve clearly thought deeply about what they are developing and the situations their version control tools need to cope with.
That leaves Subversion–which we already use, but it’s worth evaluating again, Mercurial, Bazaar, and Git. All four had pretty vibrant communities, and were being adopted by many projects.
Evaluation Criteria
I didn’t write down every aspect that I was judging these projects on, but I did have a mental list of things that I wanted to understand beyond community and adoption. I won’t touch on all these points for all the tools either (there’s not enough time in my day for that article), but I did keep these things in mind when evaluating the tools. Here is my evaluation criteria:
-
How does the tool help us solve problems that we face? To be honest, there needs to be a strong reason to not use Subversion. It solves most of our needs, and when it doesn’t, I can help fix that. I also trust the community. They are a great crew to work with, and that’s hard to give up. The next tool must offer some significant advantages, or it’s simply not worth the trouble. The two biggest problems we face are disconnected operation and we’d like to implement pre-commit code reviews (or something like them, depending on the particular tool).
-
Is the approach to version control sound? What’s their story? What problems are they trying to solve? Did they succeed? If so, how well? This is somewhat tied to the architecture, but at this point it’s more of a conceptual thing rather than the concrete implementation.
-
Is the project’s architecture sound? This seems like a funny thing to evaluate, but it’s really important. A complex architecture likely means: it’s hard to maintain, it’s hard for new developers to contribute, that there exists more bugs–and more subtle ones at that, and I think it reflects on the core values of the team developing the project. This is an entirely subjective metric, but I did evaluate architectures.
-
Is reliability important to the project? Seriously, you can’t talk about tracking the entire history of your project and not bring up this subject. The tool can’t be blowing up in your face all the time. It has to be relatively free of bugs, especially at the layers that are storing your data to disk.
-
Does the community feel documentation is important? And not just documentation for the sake of it. Documentation aimed at helping to get folks on board and using their tools quickly. Advanced features need to be well documented as well. Once you move beyond newbie status, you want to be able to use the tool efficiently to solve your problems. Are there any books? Yes, I read them! Lots of them! And so do my employees.
-
Is the command line interface intuitive? Yes, gui tools are important, but by far and large, we use the command line. It helps if it makes sense, and is easy to use.
-
Are gui tools available? While I’m a significant user of the command line, there is no discounting having guis available for browsing history, side-by-side diffs, and tools for the less command line inclined. Having a healthy set of gui tools also helps those who don’t rely on the command line as much. This also includes things like integration into popular IDEs, such as Eclipse and NetBeans.
-
Is it cross-platform? Our preference is Linux, but we do need to use Windows and Mac as well. So it’s important that the tool works well on all three platforms, and has cross-platform features–such as handling end-of-line styles.
-
Can it handle binary files well? We do need to check them in. Think documentation, images, firmware, etc. It would be nice if the tool worked well with large binary images too, since we occasionally need to version large binary images that are tied to our codebase (as a dependency, not an artifact of our build).
-
What hosting choices are available? It’s great that this wave of DVCSes allows you to keep a repository locally, and share changes via email, etc. As a business, we need to have a central location where the project lives, and we need certain features. The primary one is access controls. Not everyone has access to particular projects, plain and simple. Having some canned solutions that Just Work goes a long way towards helping corporate users and larger teams adopt the tool.
-
Are commercial vendors integrating with the VCS? Most of our infrastructure is based on open source solutions, but it’s important that more commercial entities adopt the product too. Why? Because there just might be a commercial tool that we want one day. For instance, Quickbuild is our CI tool of choice.
-
What’s the backend storage format? Is it accessible by me. Bugs happen. Hardware failures happen. Change happens. It’s important to me to have the ability to examine the backend store and extract my data, if I need to.
I’ve helped numerous people recover their data from Subversion servers that have fallen over dead, had memory failures (and silently corrupted the on disk representation), or had a faulty disk. Proper backups help immensely. But I believe in protecting my investment on several layers, and being able to extract my data from a broken backend is rather important to me.
Additionally, there is the role of the backend from the users perspective. Do they need to care about what format the backend is in? Does it change often? Was that migration simple? Why was it changing? Did the devs miss something in the design of their product? Again, having a solid VCS is foundational to a team, and having to stop to upgrade their toolchains, their branches, and the server often disrupts their productivity. Time is precious.
-
Is it easy for me to contribute back to the project? This ties back into the community, but at a different level. For instance, I love kernel development, but I’m not sure I could survive being on the Linux kernel’s mailing list. So this is about me, running into an issue, and being able to contribute something back. Not only to scratch my itch, but for others too. I hate to find bugs and not fix them.
-
Operation with Subversion. Some of my customers use Subversion, and it’s nice to still use the tools that we love to operate on a Subversion repository. This is a tough road though, because Subversion’s model is different than the new breed of tools. Subversion is more of a versioned file system, while these other tools operate on branches. This difference in models means that there is going to be some loss when interoperating with Subversion. The real question is: is it tolerable? A more interesting question for us is: can me maintain long-term branches against Subversion? Unfortunately, it’s a problem that comes up more and more frequently.
Mercurial
Initially, I did not spend as much time with Mercurial because of several issues. The community seemed very small. Matt Mackall was the primary developer on the project, with few others contributing. There wasn’t much conversation on-list about features, and releases where slow. It was never clear when the next release would happen. On top of that, it was fairly buggy, at least when it came to things like named branches. To be honest, when I started following Mercurial, it was in it’s very early days, before it had rename tracking.
However, that changed. Matt and others realized they needed to engage more, and they did. They appear to have a very vibrant community, with contributions occurring from all over. They moved to a time-based release process which helps users to understand when they’ll get to see new features and bug fixes. The quality of Mercurial also significantly improved. In my last round of testing with it, I ran into none of the issues that I had nearly two years ago. Pretty early on in the project, Matt added in the ability to track renames of files, and then later tracked directory renames. It’s a very capable system.
The Pros
I need to re-iterate that Mercurial has a very thriving and active community. It’s a key requirement to any successful open-source project, and they’ve certainly attained that status.
As I mentioned earlier, Mercurial does have support for rename tracking. And despite the fact that it only tracks files, it does a superb job. I’ve been extremely pleased in my testing with how the changes were folded in when my branch renamed files, and when the target branch had renamed the files.
Performance
Mercurial has always kept performance as a top priority, and it shows. For being written mainly in Python, it’s cold start up time is acceptable (~3s on my machine). It operates reasonably fast over the wire, and has been extremely stable in my testing.
Backend design
The backend design is very sound. There have been adjustments to the backend format several times, but I can’t recall one that largely impacted the community. The team has been very diligent about not making modifications at that layer to protect it’s user base from unnecessary upgrades, and to prevent adding complexity when it isn’t warranted.
Integration
Integration with IDEs is very strong as well. NetBeans grew support for Mercurial rather quickly, and has had some time to mature. Eclipse has a plugin, and there is a plugin for Visual Studio as well. So you’re covered on many fronts. I’ve not used any of them, just read about people’s experiences with them. On the whole, it seems positive.
Cross-platform
For as long as I can remember, Mercurial has been cross-platform. It’s been in the last year that better end-of-line support has landed, but it is there and usable. End-of-line settings are tracked in a .hgeol file, that carries around with the branch, versus being a user setting, which is good for teams.
Interop with Subversion
That leaves interoperation with Subversion. When I took my first hard look at Mercurial, hgsvn was the only real solution for interoperation with Subversion. Since then, hgsubversion has really taken over that role, and it is very well done. For a single developer working against a Subversion server, it’s very capable.
Written in Python
This is useful for us, as we can easily create plugins or contribute code to fix an issue.
Gotta love the Queues
I’ll add one more extra tidbit, but was really outside the scope of what we do. Mercurial Queues are fantastic if you need to maintain patches against a code base. Easy to use, intuitive, and it just plain worked well.
Cons
For the most part, Mercurial’s command line interface is intuitive,
especially to someone coming from Subversion. However, I find the merging
model a bit confusing. I never really liked the idea of pulling, merging,
and committing. I think the most troublesome aspect was that in my head I’m
thinking “merge X into my branch,” but on the command line I had to use
hg pull /path/to/X to bring it in. The fetch module helps, but there’s
another issue.
Divergent Renames
There is one place where Mercurial’s rename tracking falls over: divergent renames. If you have two branches who rename the same file to different names, then you’ll get a warning about it:
note: possible conflict - foo.txt was renamed multiple times to:
baz.txt
bar.txtBut the working copy won’t complain:
$ hg st
M baz.txtI expected a tree conflict. Something to say “you really should resolve” this issue. Unfortunately, it leaves me–the user, wondering how I’m going to fix this issue.
The problem I see with the fetch extension is that it’ll do all three steps: pull, merge, and commit. It didn’t care there was a warning about a possible conflict, it just committed. Now, I can fix it after the fact and before I share it with others, but it feels like the tool should be helping me out more.
No co-located branches
One thing I’ve really grow to dislike is having branches live in separate folders. Now, I’m a big user of Vim–though not an expert user. However, I do use an actual IDE, like SlickEdit to help navigate large source trees. Having to keep separate folders for branches means copying project files around, or re-creating the project workspace. Both of which are painful. Git’s branch model is really what I’m after, and Mercurial’s bookmarks will get you close, but it’s not the same. Named branches work for long-term stable branches, and they’re nice, but too heavy-weight for feature development.
Limited interop with Subversion
While hgsubversion works incredibly well, the disparity between Subversion’s and Mercurial’s versioning model means it’s difficult trying to maintain a long-term branch in Mercurial. The constant rebasing, and issues that surround it seem just a bit too much for a team maintaining a long term branch in Mercurial to handle.
Lack of great gui tools
Lastly, I’m not really keen on the gui tools. While this is less of an issue for myself (although, I’m in love with QBzr), the gui tools seem subpar–with the exception of TortoiseHg. TortoiseHg is gaining support for other platforms, which will help greatly. MacHg seems like a decent alternative if you’re on a Mac. CuteHg appears to be similar to QBzr, but when I tried it out, it died (as in the process died unexpectedly versus getting a traceback).
Lack of self-hosting solutions
The best one I found was Rhodecode. You can use Apache for
authentication and authorization, although it can be a real chore to configure
and maintain. It’s generally not the solution that we shoot for because of
the maintenance headache, but it’s doable. It would help more if system-wide
hgrc allowed you so specify permissions for individual repos, rather than
having a global allow_push flag.
Summary
Unfortunately, I just couldn’t get over Mercurial’s branching model, and how you perform merges. It’s simply too much work to keep moving project files around, and it’s too much work for me to keep the merging strategy in my head.
Bazaar
When I originally started looking at Mercurial, Bazaar, and Git years ago, Bazaar was the only one with “True Rename Tracking.” However, it was plagued with a slow backend, and what seemed like an endless stream of repository formats. Fortunately, they heard their user community, and settled on one that has remained unchanged for quite a while now.
Early on, the Bazaar community seemed more vibrant than it does today. The was a great deal of talk on list, reviews were happening on list, and a fair amount of discussion was on list as well. That has changed. I’m fairly certain there is much discussion behind the scenes between the developers, out-of-band from the list. Unfortunately, that doesn’t go far if you’re trying to build a community. Simply having conversations out in the open give folks a chance to see what you’re thinking, where things are going, and some of the problems in achieving those goals. At this point, I’m uncertain what the hot-button issues are, and what the team is doing next.
My interactions with the team have been great though. Martin Pool, the project lead, is even keeled, and I think very pragmatic. John Arbash Meinel also digs deeply into problems, and produces some dramatic results.
Pros
Command-line UI
I found the command line very accessible, as did several others that I work with. They maintained much of Subversion’s jargon and names, which made it easy to jump into Bazaar and run. The extensive help available at your fingertips is just plain awesome.
Great GUIs
Myself and my team has grown quite found of QBzr. In particular,
qlog, qcommit, qdiff, and qblame. qlog is just
an incredible piece of work when it comes to exploring history–something I
find myself doing rather often. I’ve mentioned qlog before on this
blog, so I have a screen shot lying around:
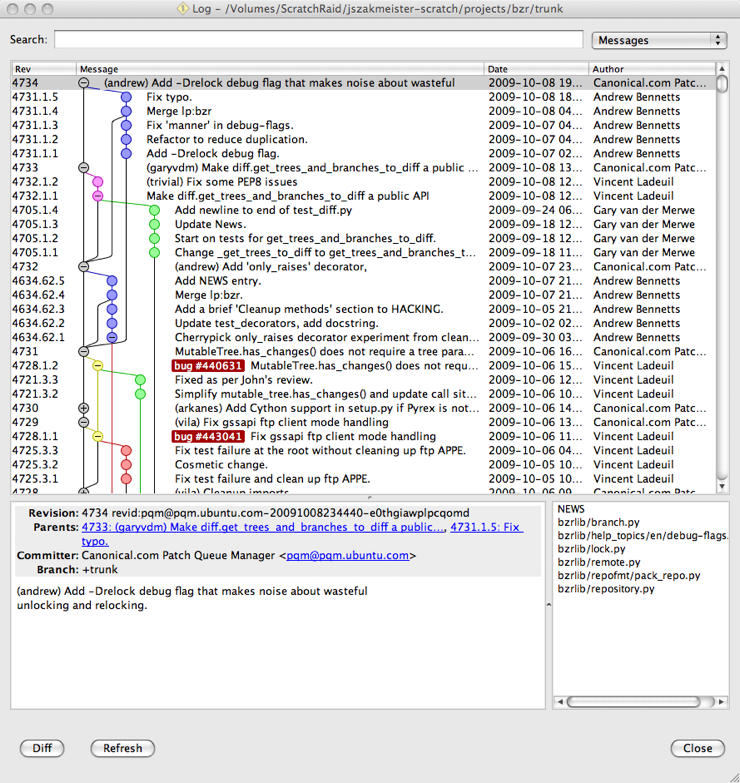
There is also BzrExplorer which builds from QBzr to provide a Windows Explorer-like view into your project. I personally don’t like that style, but many others do, and they rave about BzrExplorer.
True rename tracking
It works very well, when Bazaar is at both ends. Underneath the hood, it tracks files using file ids, and the file id stays with the file for it’s entire lifetime. It makes rename tracking easy.
Incredible interop
Jelmer Vernooij created bzr-svn years ago, and it’s just plain amazing. It supports Bazaar’s native merge tracking, as long as you’re willing to let it set some revision properties in target Subversion repository. On the whole, it’s pretty stable, and well-maintained.
But Jelmer didn’t stop there. He went on to write a git backend end in Python, called Dulwich. Then proceeded to develop bzr-git to interact with Git repositories. And if that wasn’t enough, he’s been the primary source behind bzr-hg, a plugin to help Bazaar interoperate with Mercurial repositories, as well.
The aspect that I really enjoy here is that I can work with whomever in their native system, and still get work done using tools I enjoy.
Good cross-platform support
The team takes Windows support seriously, despite the occasional lag when producing binaries. They’re pretty keen on tackling any issues that arise, and have even set up a build bot to test on Windows.
Written in Python
‘nuff said.
Cons
In fairness, there may be more here than others because we seriously considered Bazaar as a replacement for us. We’ve been using Bazaar in a limited sense, on a couple of large projects that need to interop with Subversion. Therefore, we have much more time under our belt with Bazaar than we do with Mercurial, and even Git. Don’t take this list of issues at face value: we discovered more about it because we’ve been using it longer.
On top of that, we’ve been using Bazaar for long term branches where there is more than a weeks time between integrating with trunk, which is located elsewhere. That’s unusual. You don’t find that much in other environments, but it’s something we have to live with for the time being. On this front, none of the other tools can integrate the same way that Bazaar can. In other words, Bazaar is doing what no other tool can at the moment: long-term branches that are backed by Subversion, and don’t require us to rebase… ever.
Branch-wide end-of-line style support
Bazaar has a concept called Content Filters, which can be used to support end-of-line styles. Unfortunately, the content filter rules can only live in the user’s configuration, which does absolutely no good for users who don’t share your configuration. The headache of making sure consumers of the branch all have the right settings is just too high.
All of that said, Bazaar is looking to add that support… I just don’t know where it falls in the grand scheme of things.
Architecture
I feel a little conflicted in mentioning this, because I believe it’s probably the architecture that allows such great interop, but I feel like it’s a bit over-engineered. I realize the need to expose things for testing, to allow for changing backend formats, and other things. However, I feel like there are layers upon layers upon layers. It’s made it difficult to get to know the code base, and pinpoint the specific problems that I’ve run into. I think it’s felt in other ways too, like the following issue.
Cold-startup time is too long
Mercurial wasn’t extremely fast in this department either, but it was
consistently 3-4 seconds. Bazaar, on the other hand, tends to run me upwards
of 6 (for a bzr st that’s not in a working tree) to 14-15 seconds before
seeing any output. I didn’t think it was all that important, until I was
working on several different projects and things would fall out of the file
cache. Working on several projects is pretty much the norm for us, and it
was a fact I hadn’t considered in testing until I ran into this problem.
Tree conflicts can get unwieldily
This is another situation where our prolonged use of Bazaar has exposed a few things to us. The issue is what happens when you have divergent renames–person A renames the file to X, and person B renames the file to Y? What if they both made modifications as well? Or, person A renames the file but person B deletes it?
It’s easy to find yourself in a state where you don’t know what is happening. At the moment, out of the small team of folks using Bazaar, I’ve been the only one who has been able to understand the problem fully enough to resolve it.
So there is actually a plus and a minus here. Bazaar knew there was a problem, and was able to detect and communicate it. However, the brain power to recover is a bit too high. Some of this relates to the jargon surrounding the types of conflicts: contents conflict, path conflicts, text conflict, duplicate entries, and a few others. While generally helpful, there were instances where the terminology gets in the way of understanding what transpired to get to that point.
Lacks self-hosting solutions
Caveat: I did set up something, that works, but I’m not happy with it as a solution. It’s way too much work for a small team, it would be unbearable for a larger team.
Setting up our own SSH solution just plain isn’t going to happen. We refuse to set up SSH accounts to servers for everyone, and setting it up to happen through a single account means that we need to implement our own permissions system. I’m sure there is a solution here somewhere, but I wasn’t willing to tackle that problem. bzr-access attempts to solve that problem, but doesn’t go nearly far enough.
Setting up a web server to host the repositories is nearly as painful. The crux of the problem here is that just serving the branches over plain HTTP is not enough: Bazaar is too slow in that case. Which means, we need to use Bazaar’s smart server over HTTP. That requires being able to POST, to the branch, and the shared repo, if you have it set up that way.
Unfortunately, Bazaar also falls back to plain HTTP access in a number of cases, which we don’t allow at all, because we want to make sure we have the opportunity to grant access correctly. This means we need to make sure to use bzr+http:// everywhere, because it’s the only way that keeps Bazaar from falling back to plain HTTP access.
So, in short, it works but we’re not happy with the solution.
Keep running into bugs that I can’t reproduce
For instance, this one. I’ve hit it a few times, and went through hoops to recover from it. I spent hours trying to reproduce and ultimately failed. But the bug hurts, and we’ve hit it a few times.
Summary
I like Bazaar… a lot. The client side tools are fantastic. Anyone on our team who touches QBzr quickly falls in love with it.
Unfortunately, the lack of a real hosting solution with access controls really hurts. The few bugs we’ve run into really hurts. And let’s be clear, the only seem to show up with Subversion interop. Bazaar works well when operating on plain Bazaar branches. Unfortunately, we need Subversion interop. I don’t believe this is a function of bzr-svn. Instead, I believe that bzr-svn pushes the limits the backend rather hard, and these are edges that keep falling out when using bzr-svn.
And while bzr-colo get you colocated branches (to avoid having a directories for branches), it too has some bugs that we’ve been unable to reproduce (and we can’t share the branches).
Finally, the distinct lack of chatter on-list leaves users in the dark about Bazaar’s roadmap. I wish there was more discussion out in the open, instead of on IRC channels or internal Canonical lists. At the end of the day, we need to see a thriving community, and I’m not seeing it right now.
Git
Git has an interesting history with it initially being developed by Linus Torvalds as a replacement for BitKeeper after the fallout with Larry McVoy. When developing Git, he took his favorite aspects of BitKeeper and incorporated many ideas from Monotone as well. From the beginning, Git has been focused on performance.
Git’s community evolved very quickly. Spill over from the Linux kernel community–and their intense dedication it–helped power Git early on. They needed a replacement for BitKeeper, and nothing was going to stop them. As time went on, that support only got larger. They’ve been very effective in growing the community, and harnessing that energy to get work done.
Pros
Git is fast
Linus wrote much of the foundation of Git, and there is no one better qualified to eek every last bit of performance out of Linux. The result is one of the fastest version control systems ever built. Many of the day-to-day operations are lightning fast, and where you start to pay is if you’re going to dig into history more (like blame, or following renames).
Colocated branches
With Git, it’s very simple to start a new branch:
git checkout -b <branch>. I don’t need to copy over any IDE settings,
and I don’t need to consume any extra space on my hard drive. They’re easy
to switch between, and Git is built on this model versus being retrofitted.
As a result, this workflow is easy and smooth. It’s probably my favorite
feature of Git, at the moment.
Rebase capability is insanely good
Early on, I exercised all 3 version control systems, and the rebase ability in Git at the time was just “meh.” That’s far from the case today. It’s ability to recognize similar commits and not re-apply them is phenomenal. It’s ability to Do the Right Thing when the trunk has been integrated a few times is also phenomenal. For us, it’ll make long-term branches against Subversion repos possible (even after we dcommit the results).
Submodules
Some projects are just plain large. Git’s submodule support provides the ability to pull other projects in as a subtree in your project. I didn’t do an very in-depth setup with submodules, but I did spend some time working with them to understand the workflow better. I like them. I particularly like the fact that you can re-map them, since we’re often faced with completely disconnected operation.
Backend architecture
While I can’t say I’m thrilled with the amount of perl, shell, tk, and what seems like a zillion other languages involved in the codebase, I can say that I really like the backend architecture. It’s simple, clean, elegant, and fairly easy to understand. I feel the same way about Git’s backend as I do Subversion’s: if there is a problem, I can dig in and figure out what the problem is and how to fix it. That’s important to me.
Server-side self-hosting options
Of the three, I feel like Git offers you the most in terms of server-side hosting options. There is Gerrit, Gitolite, Gitorious, and even commercially available alternatives such as GitHub:FI. The two that standout to me are Gerrit and GitHub:FI. Gerrit has built-in code review support and access controls. It can also authenticate against LDAP, making it easier to fit inside an enterprise environment. GitHub:FI is basically GitHub rolled up into a deployable package on your own infrastructure. GitHub is just plain awesome. Access controls, code reviews, plus the ability to work with forks and share between them is simply amazing.
Cons
Hard to learn
Git kind of redefined some common terms in version control, and then added
it’s own into the mix (git reset, for example). Coming from another
VCS requires partially rewiring your brain. On top of that, throw in the
complexity that a distributed system brings into the mix… and well, I’ve
got some training to do. Merge graphs, local commits, pushing, pulling…
it’s a lot for developers to learn.
I will say that more recently, Git has been very good about suggesting the right course of actions when things happen. This helps tremendously. I welcome any improvements on this front.
The documentation is also coming along. It was pretty sparse before, but the community has made great strides in closing that gap. And there are several books out there now, making it easier to get started.
GUI tools are a bit lacking
I realize that Tk is just about everywhere, but c’mon… it’s just plain ugly. I guess that’s the difference between the form vs function mindsets of engineers. But I want both. Something equivalent to the beauty and function of QBzr would be most welcome.
Seriously, better solutions for non-technical folks would be very nice. Subversion’s WebDAV auto-versioning support is awesome on this front. It helps the management types to put in their data, without resorting to having a dev do it for them.
Windows support isn’t first class
I guess I should temper my expectations considering that the guy who wrote the Linux kernel wrote Git. Right now, msysGit is it for us. I really dislike that Windows support is maintained separately from Git itself. However, there is obviously some cooperation between the two projects, as I believe some of Git’s C code came from msysGit (to improve performance on Windows).
I’m not knocking msysGit. I just wish that msysGit was exactly identical to Git, but worked well out-of-the-box on Windows–in much the same way that Subversion does. I hate Windows as much as everyone else, but a lot of development still takes place there.
One example of where things don’t work well: git blame when
core.autocrlf is turned on. It shows every line as currently modified in
the working tree. FWIW, I’m not sure we need that setting. Most of our editors
are aware of line-feed only files and edit them in the appropriate line-ending
style. Plus, git attributes present a better way to deal with eol style in
general, especially for cross-platform projects.
Another issue for me was I couldn’t get git-cheetah to run in Explorer. I ran the installer several times, and things were installed… but I never found out how to make it run.
An SSH agent comes with msysGit, but I believe using PuTTY is probably a better path as it integrates into Windows better. There is some documentation on how to do this in An Illustrated Guide to Git on Windows.
Unicode paths are still an issue
At the moment, Linux treats paths as a byte-stream. There are on-going discussions about how that should be handled in the future. This is a problem on both Linux and Windows, since different locale encodings can result in different encodings of path names. There appears to be some heat around the discussion (no one wants to make Git slower on Linux). OTOH, I don’t know how you can add functionality without affecting performance somewhat, and good i18n support would seem to be right up Linux’s alley.
Summary
I love Git’s branching model. Bazaar’s and Mercurial’s attempts at bolting it on have come close, but ultimately fail–they just don’t work the same.
Git also has a number of options for serving git repositories, many of which incorporate some level of access controls. Gerrit and GitHub:FI are the two that stand out the most in my mind. We’re currently evaluating GitHub:FI, and we’ll likely chose it as our hosting option.
We’ll need to do some internal training to get everyone’s mind set switched over though. The daily operations are different enough that we need to do something to keep employees from getting confused and to give them some ammunition for solving most problems themselves.
I really wish there was a better option for Windows, but the command line client does work.
General observations
The big three DVCSes all suffered from a set of common problems:
-
None of them are adept at handling large binary files. Git at least claims to be a “source code management” tool, which by definitions means it wants to be handling text most often. However, these things do come up. Prepare for some awful performance if you try to version control large files, and you may eventually cause the tool to consume memory until it’s killed by the OOM killer, or it actually does consume all the free memory on the system.1
-
None of them support advisory locking. To be honest, I’m not sure it makes sense in a purely distributed model. But it does mean there needs to be a different level of communication happening between developers to keep them from changing Word documents simultaneously. That gets a bit cumbersome because it means I need to constantly monitor email, IRC, or some other comms channel.
-
You need to understand graphs. You can get up and running with any of the DVCSes rather quickly, but becoming proficient requires understanding graphs and how the tools are manipulating that graph. Once you understand it, you quickly go from beginner to advanced user. Obtaining that knowledge can be a steep curve, especially for those who haven’t dealt with graphs as part of their education (Electrical Engineers and the like).
The Choice
Hopefully, you can see that arriving at a decision has been a long process. We take version control pretty seriously.
For us, the disconnected operation case is playing more and more of a role, and that also involves Subversion interoperation. None of the current DVCSes take their interop far enough to be a complete replacement for ever using Subversion:
- None of them cope with svn:externals. And even if they did, they probably wouldn’t cope with externals that point to a subtree of another branch.
- None of them turn
svn:eol-styleinto equivalent setting in their own system (git attributes, for instance) and setsvn:eol-styleon new files. - None of them do anything with Subversion’s autoprops.
- None of them care a bit about what Subversion’s
svn:mergeinfosays. This is most likely because Subversion doesn’t have branches as first-class citizens, and that Subversion doesn’t keep a merge-graph in the same way the DVCSes do.
All of that said, Bazaar is really the best interop performer here, with the exception that I’ve managed to get a few branches into a state where they were no longer usable. When that happened, it was terribly painful to recover. That sent me searching again, looking to solve a few shortcoming we were facing with Bazaar. Mainly, something more reliable when integrating with Subversion, a better branching model, and better hosting solutions.
Mercurial is still very interesting to me. I really like some features, like Mercurial Queues. Mercurial is fast, well designed, and has seen a lot of uptake (even Microsoft is supporting it in CodePlex!). However, it still suffers from some similar issues as Bazaar: we don’t want separate directories for each branch, and the hosting solutions are a bit limited. In fairness, there are a few viable hosting solutions:
-
Kiln from FogCreek Software. It’s a Windows only solution though, which pretty much removes it from my list. It does appear to be a nice interface though, and has built-in support for handling large binary files. I’m not sure how well that actually works though.
-
Assembla. They have a private install solution that supports Subversion, Mercurial, and Git. I haven’t tried it either, as it doesn’t seem like a compelling solution for us.
-
RhodeCode. Interesting open-source project, but I don’t think it’s quite ready for us yet.
And there seem to be more popping up recently (just discovered django-projector, for instance).
The other issue was some of the failure modes of Mercurial (see Divergent Renames above).
Then there is Git. Git has been on the radar since it came out. With all of the controversy surrounding BitKeeper, it was neat to see what the Linux community would come up with. You can still see some remnants of those decisions today. For instance, the overwhelming mix of perl, python, shell code, etc. that makes up the code base.
Git has come a long way since its early days. Git’s rebase and merge algorithms seem almost like black magic. What really attracts my attention is its branching model. It’s just so nice and easy to work with, and I don’t have to worry about setting everything up again every time I branch (yes, I do use an IDE, mainly to navigate C code). The storage model is easy to understand, and flexible. And the sheer number of tools being built on top of Git is just plain phenomenal. There are also some nice private hosting options out there, and several with built-in access controls.
Git’s weaknesses are:
- It’s Windows solution is not maintained the main repository, and thus, feels like it’s not as big concern to the Git community as the Unix variants.
- The lack of a good graphical tools to use on anything but Mac OS X.
You might throw the path encoding issue in there too. Although I feel like that’s going to come to head and will get addressed at some point soon. Also Git’s staging area and its jargon make it more difficult to learn the tool, especially if you’ve been exposed to other version control systems.
The plus side is that it performs better than any other VCS I’ve touched. It’s clear the team has put a lot of time and effort in making sure that it performs for probably one of the hardest use cases in the world: the Linux kernel.
So where do we go from here? We’re going with Git. Does that mean I stop using the other tools? No. It just means that for my company and our work, we’re going to migrate to Git as our version control tool of choice. I expect that transition to take some time as we get all of repositories converted, and the infrastructure finally squared away.
As for Subversion, I’m actually kind of excited. I see several areas where we can learn from these tools. I, personally, expect to be using Subversion for years to come… and I don’t have any qualms with that.
-
Kiln does appear to support versioning big files, although via a separate extension called kbfiles, which is based upon another extension called bfiles. ↩