The bug trifecta of death
All software has bugs. As humans, it is in our nature to make mistakes. We forget, make typos, become distracted and implement something wrong. It happens. You know what else happens? Habit. For instance, we get into the habit of relying on our toolchain, and our operating systems. So it’s a real surprise when things don’t work quite like you expect.
Bug 1: Using an uninitialized variable
It was a very simple snippet of code:
unsigned int
foo(const char *key, unsigned int size)
{
unsigned int spaceNeeded;
if (key)
{
spaceNeeded += 16 + size;
}
else
{
spaceNeeded = 0;
}
// ...
return spaceNeeded < spaceAvailable;
}Can you spot the bug? It’s in the body of the first if expression:
spaceNeeded += 16 + size;Here is a classic case of using an uninitialized variable. The expectation is
that spaceNeeded will sit at some location on the stack, and who knows
what value it starts with–it’s effectively a random value. It’s not completely
random though. The execution of your program is what actually affects it. So
if it runs the same way every time, it’s likely you’ll get the same value on the
stack every time.
So here’s where the string of failures begins. In your normal, every day routine, you expect gcc to give you a warning:
foo.c:8:17: warning: ‘spaceNeeded’ may be used uninitialized in this functionUnfortunately, that didn’t happen. Instead, I got nothing. We did end up with an interesting behavior at runtime though. The function almost always returned true. Because of some of the other calculations, the unit tests didn’t trigger a bad path through the code. So, it passed, and all was seemingly well… until I happened to be doing something else and discovered the problem. And yes, it was code reviewed, but the issue was missed somehow.
The search begins!
Once I found the problem, I went on the manhunt to determine why gcc had not warned us about it. Turns out that gcc is actually rather bad about this. There’s a bug in the bug tracker for it: Missing ‘used uninitialized’ warning (CCP). Here’s an interesting excerpt:
BTW, in my review of Wuninitialized problems, this is problem number 1 of missing warnings, as evidenced by the number of duplicates. So even alleviating this in simple cases would be a major improvement.
In the middle of the thread is this:
We are not going to fix this.
Ugh. Not what I want to hear. Sure enough, I compiled the latest version of the
compiler, and it’s not fixed (the ticket is still open, so that’s no surprise).
It turns out that the problem is really quite difficult. In fact, they’ve
tracked the issues here in the GCC
wiki. Unfortunately, it
doesn’t help poor souls like me. What I did find is disabling that optimization
pass brought out the warning. I did that by passing in -fno-tree-ccp to
gcc. This disables Conditional Copy Propagation (CCP), which can result in an
increased size, but it seemed to be fairly limited in this particular code base.
I’ll also be looking at some other sort of lint tool, or integrating clang to help bring about these errors. The only problem is that sometimes these tools can give quite a few false positives, require extensive customization, and can be difficult to integrate into an existing build process.
Bug 2: Flush your caches
I’ve been doing quite a bit of Linux work on the ARM processor lately, and the team ran into a problem where memory mapping files on a custom block device was seeing data corruption in user-space. It was an extremely simple test: open device, write data across its entirety, check it, write new data across its entirety, check it and watch it fail. Sometimes it would take more than one iteration of this, but it often failed rather quickly.
The bigger issue was using the device as swap space. Programs would crash with apparent random data corruption. And the crash seemed to reference data we were using in another application.
Got some cache?
Because of the alignment of the corruption, someone was able to determine it was
cache-related, and found that the could change the behavior (for the better) by
setting the cache policy to be write-through. But you could still induce errors,
and having a write-through cache policy means giving up some performance. The
Linux kernel has an awesome document written by David Miller. While
reading through it, I ran across a function called
flush_dcache_page() with a handy little note that
says:
The phrase “kernel writes to a page cache page” means, specifically, that the kernel executes store instructions that dirty data in that page at the page->virtual mapping of that page. It is important to flush here to handle D-cache aliasing, to make sure these kernel stores are visible to user space mappings of that page.
Don’t forget to flush!
Argh. This is exactly the problem. Whenever a block device responds to a read
operation, and loads data into a buffer, it needs to make sure said data gets
flushed to make sure the user space mappings can see the new data. Sure enough,
we weren’t doing that. Note that on the x86, this is unnecessary
(flush_dcache_page() is a no-op).
Cache aliasing
The crux of the issue is that the ARM processor we use has a virtually-indexed, virtually-tagged (VIVT) cache1. These types of caches are prone to aliasing problems–where more than one virtual address points to the same physical memory location:
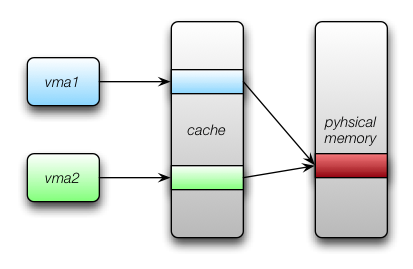
When the data makes it the block device, it’s arriving being referenced by
vma1, but at some point, we have to map it to vma2. Since the cache
doesn’t know that writes going to vma2 should invalidate the cached
content for vma1, we must tell the operating system to do it on our
behalf. Otherwise, when the operation is complete, the application will see
stale data for the address. They won’t see some of the freshly written data.
To complicate matters, this also depends on your data access pattern. It’s possible that things work fine for you, but still have this bug because the data access pattern means that the data has fallen out of the cache. This is what makes cache aliasing problems so tricky to debug: the corruption almost seems random.
Policy matters
The final wriggle is that problems also depends on your cache policy. The default cache policy in Linux is writeback, and for good reason. With this policy, the data will be retained into cache until it’s ready to be written to physical memory. This keeps the processor from having to consume expensive memory cycles talking to the physical memory.
With a write-through cache policy, data always makes it to the physical page.
However, you could still read invalid data if data was written via vma2,
but data was already cached for vma1. So it’s not a panacea.
First attempt at fixing the issue
Okay, so I added a call to flush_dcache_page() after reading data from the
device into the final buffers, and things improved considerably, but the problem
wasn’t completely fixed. We took a look at brd and found an interesting
snippet of code:
mem = kmap_atomic(page, KM_USER0);
if (rw == READ) {
copy_from_brd(mem + off, brd, sector, len);
flush_dcache_page(page);
} else {
flush_dcache_page(page);
copy_to_brd(brd, mem + off, sector, len);
}
kunmap_atomic(mem, KM_USER0);Interesting! There is a flush before it does the copy for a write! I just
didn’t expect to have to do this. I thought Linux would have made sure that
things were clean already, but apparently not. Tracking this down further, I
found the
commit (c2572f2b)
that introduced flush_dcache_page() in the write path. Here’s the commit’s
log message:
brd: fix cacheflushing
brd is missing a flush_dcache_page. On 2nd thoughts, perhaps it is the pagecache’s responsibility to flush user virtual aliases (the driver of course should flush kernel virtual mappings)… but anyway, there already exists cache flushing for one direction of transfer, so we should add the other.
It seems to indicate the same logic I had about it. But it looks like the particular version of the kernel doesn’t do that (or maybe, it’s undefined, and you must still handle it). It’s not clear from any documentation I could find whose responsibility it is. Hey! Why not check a driver book. Go ahead. See if it mentions one iota about this problem. I’ll wait.
You probably found what I did… nothing. We added the flush in our driver’s write path–before copying the data from the pages to the device, and that fixed the other half of the problem. It’s rock solid now.
The worst part…
I believe the issue that bothers me most about this issue is the lack of documentation and instruction surrounding the need for flushing the caches. It’s not clear at all that as the author of a block device driver, I need to flush the incoming pages. And as I mentioned before, not a single Linux device driver book mentioned it either. I would think the kernel would document somewhere what the terms and conditions are for an interface. But, apparently, you just need to know.
So, given the fact that we screwed this up badly, what about our other block devices in the system? You know, the ones included in the kernel.
Bug 3: Quit with the flushing already!
There are two other block devices you typically use in an embedded system: mtd, and the mmc/sdcard. The mtd driver is used so you can utilize flash to run the operating system from, or to use plain flash as storage space. The mmc driver is used to communicate to SD cards (for cameras, phones, and other general storage). We make use of both drivers, so it was time to investigate.
Look at MMC first
We use the SD card as read/write storage, so there’s the potential data is modified, but could be stale. I spent hours trying to follow the flow of data to see if things were being flushed in all the right places. The driver is a bit of a bear to penetrate, especially in such a short time frame. I started closer to the hardware, and tried working my way up. That was proving to be difficult, because of all the abstractions that are in place. So, I tried to come in from the top, and follow the path down.
“There be dragons”
I, personally, haven’t had much to do with block devices, so this was all pretty new to me. There is a block subsystem that provides a number of capabilities, and the mmc was using it to coordinate its work.
While researching some of the cache-flushing issue above, I ran into this commit (ac8456d6), which says:
bounce: call flush_dcache_page() after bounce_copy_vec()
I have been seeing problems on Tegra 2 (ARMv7 SMP) systems with HIGHMEM enabled on 2.6.35 (plus some patches targetted at 2.6.36 to perform cache maintenance lazily), and the root cause appears to be that the mm bouncing code is calling flush_dcache_page before it copies the bounce buffer into the bio.
The bounced page needs to be flushed after data is copied into it, to ensure that architecture implementations can synchronize instruction and data caches if necessary.
Well, mmc makes use of that indirectly, and our version of the kernel didn’t have this bug fix. It get more interesting though, because there is still the issue of making sure the user-space mappings get flushed.
It turns out that the mmc driver in our version of the kernel is just plain broken. It appears that all the lower-level copies have the flushing done correctly, but not when the request first enters the driver.
So, we have another cache-flushing problem in that driver. Great. Core Linux code too.
And mtd?
The mtd driver was much easier to follow. Digging through the code, I found
do_blktrans_request(), which is handling the cache-flushing
work:
switch(rq_data_dir(req)) {
case READ:
for (; nsect > 0; nsect--, block++, buf += tr->blksize)
if (tr->readsect(dev, block, buf))
return -EIO;
rq_flush_dcache_pages(req);
return 0;
case WRITE:
if (!tr->writesect)
return -EIO;
rq_flush_dcache_pages(req);
for (; nsect > 0; nsect--, block++, buf += tr->blksize)
if (tr->writesect(dev, block, buf))
return -EIO;
return 0;
default:
printk(KERN_NOTICE "Unknown request %u\n", rq_data_dir(req));
return -EIO;
}Heh. Apparently, they’ve run into the cache-flushing issue as well, because
there’s a call to rq_flush_dcache_pages() there in the write path.
With a quick invocation of git gui blame, I found the commit (2d4dc890)
that introduced the
line:
block: add helpers to run flush_dcache_page() against a bio and a request’s pages
Mtdblock driver doesn’t call flush_dcache_page for pages in request. So, this causes problems on architectures where the icache doesn’t fill from the dcache or with dcache aliases. The patch fixes this.
The ARCH_IMPLEMENTS_FLUSH_DCACHE_PAGE symbol was introduced to avoid pointless empty cache-thrashing loops on architectures for which flush_dcache_page() is a no-op. Every architecture was provided with this flush pages on architectires where ARCH_IMPLEMENTS_FLUSH_DCACHE_PAGE is equal 1 or do nothing otherwise.
See “fix mtd_blkdevs problem with caches on some architectures” discussion on LKML for more information.
I didn’t sit down to read through that thread, and instead, focused my attention back on the mmc driver, since it’s pretty clear the mtd guys have dealt with this issue.
-
Information on the different kinds of caches and some of the issues can be found here. Specifically, the section on address translation. ↩